問題
結果は 57位
方針
LightGBM 1本で戦いました。
- test データに存在するユーザに対して train データに含まれている場合と含まれていない場合で 2つモデルを用意して予測
- 考えた特徴量をすべて突っ込んで LightGBM さんに頑張ってもらう
コード
既存ユーザ用
https://github.com/siman-man/atma_cup_15/tree/model-for-seen
新規ユーザ用
https://github.com/siman-man/atma_cup_15/tree/model-for-unseen
特徴量
アニメ
数値データのものはそのまま採用
type, rating, source, rating は label encoding
| rating(before) | rating(after) |
|---|---|
| PG-13 - Teens 13 or older | 1 |
| PG-13 - Teens 13 or older | 1 |
| PG-13 - Teens 13 or older | 1 |
| R+ - Mild Nudity | 2 |
| PG-13 - Teens 13 or older | 1 |
| PG-13 - Teens 13 or older | 1 |
| R - 17+ (violence & profanity) | 3 |
- genre は one-hot encoding
| Comedy | Sci-Fi | Seinen | Slice of Life | Space | Adventure | Mystery | Historical | Supernatural | Fantasy |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 |
- aired は存在する数値の中で一番大きいものを採用
| aired (before) | aired (after) |
|---|---|
| Apr 1, 2012 to Mar 22, 2014 | 2014 |
| Oct 23, 2005 to Jun 19, 2006 | 2006 |
| Apr 5, 2014 to Jun 21, 2014 | 2014 |
| Apr 5, 2014 to Jun 21, 2014 | 2014 |
| Apr 2, 1995 to Sep 24, 1995 | 1995 |
- producers, studios は区切りの中で一番先頭のものを採用。変換後のカラムに対して label encoding
| producers (before) | producers (after) |
|---|---|
| Aniplex, Dentsu, YTV, Trinity Sound | Aniplex |
| Avex Entertainment, Marvelous, SKY Perfect Well Think, Delfi Sound | Avex Entertainment |
| Aniplex, Kodansha, Delfi Sound | Aniplex |
| Media Factory, AT-X, Sony Music Communications, Tsukuru no Mori | Media Factory |
| TV Tokyo, Pioneer LDC | TV Tokyo |
one-hot encoding も試してみたが次元数が増えた割にそんなにスコアが増えたわけでは無かったので結局不採用。(モデルの学習時間が速かったら検証してこっちで採用したかもしれない)
- duration も数値に変換してそれを使用
| duration (before) | duration (after) |
|---|---|
| 24 min. per ep. | 24 |
| 24 min. per ep. | 24 |
| 24 min. per ep. | 24 |
| 1 hr. 45 min. | 105 |
watching,completed,on_hold,dropped,plan_to_watch を他の値で割ったもの
LightGBM はカラムごとの演算を手助けする必要があるそうなので、とりあえず効果がありそうなものを全部入れる。
'watch_rate_by_members', # 視聴率(watching / members) 'watch_rate_by_completed', # 視聴率(watching / completed) 'watch_rate_by_on_hold', # 視聴率(watching / on-hold) 'watch_rate_by_dropped', # 視聴率(watching / dropped) 'watch_rate_by_plan_to_watch', # 視聴率(watching / plan to watch) 'comp_rate_by_members', # 完了率(completed / members) 'comp_rate_by_watching', # 完了率(completed / watching) 'comp_rate_by_on_hold', # 完了率(completed / on-hold) 'comp_rate_by_dropped', # 完了率(completed / dropped) 'comp_rate_by_plan_to_watch', # 完了率(completed / plan to watch) 'drop_rate_by_members', # 中断率(dropped / members) 'drop_rate_by_watching', # 中断率(dropped / watching) 'drop_rate_by_on_hold', # 中断率(dropped / on-hold) 'drop_rate_by_completed', # 中断率(dropped / completed) 'drop_rate_by_plan_to_watch', # 中断率(dropped / plan to watch) 'hold_rate_by_members', # 保留率(on-hold / members) 'hold_rate_by_watching', # 保留率(on-hold / watching) 'hold_rate_by_dropped', # 保留率(on-hold / dropped) 'hold_rate_by_completed', # 保留率(on-hold / completed) 'hold_rate_by_plan_to_watch' # 保留率(on-hold / plan to watch)
レビューの統計データ
- anime_1_review_count, anime_2_review_count のようにこのアニメがどのような評価をされたのかを集計
- レビューの平均値を出すとそれに偏った値が出たので不採用
| anime_6_review_count | anime_7_review_count | anime_8_review_count |
|---|---|---|
| 0 | 2 | 7 |
| 5 | 7 | 31 |
| 2 | 5 | 13 |
アニメの名前を一部抜き出して「シリーズ名」として追加
前に amakanize というライブラリがあったなーと思い、japanese_name を split で分割したものの最初の値を入れて出てきた値を series_name として扱う。最初の名前を使ったら 劇場版 がノイズすぎたので最初に削除しておく。
irb(main):010:0> Amakanize::SeriesName.new('とある魔術の禁書目録').to_s => "とある魔術の禁書目録" irb(main):011:0> Amakanize::SeriesName.new('とある魔術の禁書目録Ⅱ').to_s => "とある魔術の禁書目録" irb(main):012:0> Amakanize::SeriesName.new('とある魔術の禁書目録Ⅲ').to_s => "とある魔術の禁書目録"
python ならなんかもっといい方法ある気もするけど手持ちの知識で戦うとこんな感じになった。
ざっとしか見てないけど大体うまくいってそうなのでそのまま採用。細かく見ていったらおかしなところもありそう。

split して先頭の値の採用なので仕方ないけど「それでいいのか」みたいな気持ちになった。

ユーザー
アニメ視聴の統計データ
train データからどの程度アニメを見ているかをチェック。train データに含まれていないユーザ対しては使用していない(使用したらスコアが下がったので)
- レビュー数
- どのジャンルを見ているかの割合
| comedy_rate | dementia_rate | demons_rate |
|---|---|---|
| 0.4634146341463415 | 0.04878048780487805 | 0.14634146341463414 |
| 0.55625 | 0.0125 | 0.03125 |
| 0.5142857142857142 | 0.0 | 0.14285714285714285 |
- ジャンルごとの平均スコア (母数が 5未満なら欠損値扱い)
| comedy_score | dementia_score | demons_score |
|---|---|---|
| 7.894736842105263 | 6.166666666666667 | |
| 7.50561797752809 | 7.4 | |
| 8.666666666666666 | 8.6 |
- レビュー点数のヒストグラム
| user_8_review_count | user_9_review_count | user_10_review_count |
|---|---|---|
| 10 | 7 | 4 |
| 66 | 25 | 4 |
| 7 | 6 | 9 |
- anime_id にスコアを紐づけたもの(数が 2000 ぐらいあって激重)
重いけどこれでスコアが上がったので採用
| 047b47eda9d02f50dd75_score | 04a3d0b122b24965e909_score | 04fddcb5918f66c618df_score |
|---|---|---|
| 6 | ||
| 10 | ||
| 9 |
他にも色々あった気がするけど大体こんな感じかも。
fold の切り方
既存ユーザ用
fold = StratifiedKFold(n_splits = 5, shuffle = True, random_state = 510) cv = fold.split(X, y)
新規ユーザ用
fold = GroupKFold(n_splits = 5) cv = fold.split(X, y, groups = train_df["user_id"])
イメージとしては既存ユーザはランダムで、新規ユーザ用は学習データの中に検証データのユーザが入らないようにすることを意識。 明らかに CV の値が LB スコアより良かったので「絶対 leak してるな」と思いつつ 相関はあったので気にしないことにした。
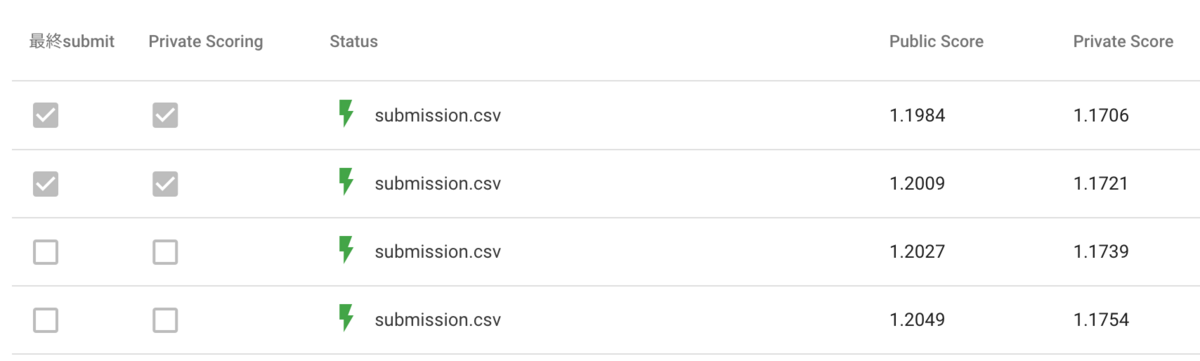
CV seen: 0.9297 unseen: 1.3881 Private Score: 1.1706
seed値を変えながら生成したモデルの予測値の平均を採用
seed値を変えて生成したモデルを複数生成してそれらの予測値の平均を取ったもとのを最終予測値として採用
感想
kaggle のコンテスト情報が定期的に流れてきては「開催期間 数ヶ月もあるのか。。。やめとこ」みたいな感じでずっとスルーしてたので、1週間という比較的短いコンテストだったので参加してみました(1週間を短期間というのもスゴイなと思いつつ)
データコンペ初参加の感想としてはまず、ディスカッションを眺めておくことで知識がなくてもある程度スコアが取れるコードが書けるというのが助かりました。
自分のコードは基本的に
#1 初心者向け講座 データと課題を理解してSubmitする!
に書かれているコードをそのまま持ってきて書き換えただけなので自分で 1から書いたのはデータの前処理部分と特徴量ぐらいじゃないかな。
pandas の操作が全然分からなかったので、Ruby で csv 読み込み -> 特徴量を追加した csv 生成 -> python で読み込みという処理を行っていた。全部 python 側で処理したほうが将来的な効率は良くなるだろうなと思ったけど結局慣れている言語で処理した。今後は python 縛りで参加するとかしないと成長できなさそう。
わからないところは全部 ChatGPT さんに聞いた。なんか賢いので ChatGPT がコンテストに出たほうが良いスコア取れそうだなと感じた。
コンテスト後半、モデルの学習時間が 1h を超えたりして正直もうちょっと強いマシンが欲しいなと思った。ローカル側で計算するのでマシンリソースはあるだけ得になりそう。
コンテストドリブンで学習するのが一番モチベが保てるので今後も似たようなコンテストがあったら参加してみたいと思います。(あとは過去問を見て学習)
ヒューリスティックコンテストとの違い
一番の違いを感じたのは CV (Cross-Validation) スコアと LB (Leader Board) スコアを一致させる難易度。ヒューリスティックコンテストではローカルで常に真スコアが得られるので、ローカルで検証したスコアは submit しても大体同じ点数を取れる。(なので提出回数は最低 1回でもいいぐらい) しかし、今回のコンテストでは真スコアはサーバー側にしか存在しないので CV スコアが改善していざ submit してもスコアが大幅に悪化するなんてことがザラにあった。この場合は学習時に leak (検証データの値が学習データに漏れている状態) しているとか fold の切り方が悪いとか色々あるらしいのだが、このあたりの知見が無さすぎてかなり苦労した。(結局最後まで苦労した)
ヒューリスティックコンテストでは基本的にコンテスト期間中の解法の公開については厳禁なので、それとは違って Discussion が活発なのは初参加者としては助かった。とにかく引き出しの少なさが致命的なのでこの部分を補える仕組みがあるのは良い。ただ、常に監視していないと上位の方針が公開されたときについていけないのでそれはそれで大変だなと感じた。(コンテストによっては公開されている手法 + α でそれなりの順位とか取れるコンテストとか存在してそう)
今回のコンテストがそうなのかわからないが基本的に点差がものすごい僅差なので、private スコア (system test) による順位の変動がかなり大きいなと感じた。あと、テストデータの数も大きいなと思った。普段のヒューリスティックコンテストなら大体 2-3000 件ぐらいだけどテストデータが 10万件超えてたので。(多くても 5000件ぐらい)
すべての提出に対して private score が計算されてその結果が確認出来るので「あれを提出していたらどうなっていたかなー」みたいな事が無いのは良かった。代わりに「これを提出しておけば。。。」みたいな事がありそうだけど。 全部計算しているならその中で一番良いものを選んであげても良いのではと思ったが、ベストなものを選ぶのも実力のうちの一つなのかもしれない。