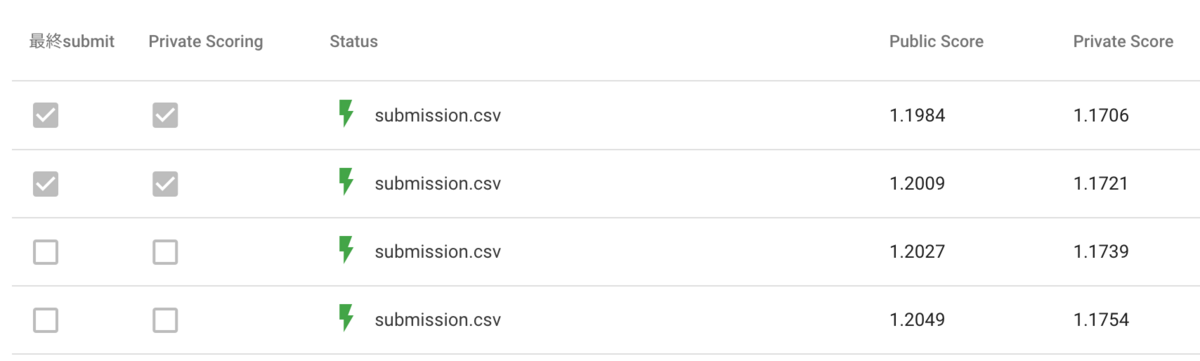
問題
提出コード
https://gist.github.com/siman-man/2218aee9a4a99e3bc6c780dbb72066ba
方針
- N と A の値からサンプリングの回数を決定
- クエリーの投げる位置を焼きなましで調整
- クエリーの結果からグリッドを生成している方程式のパラメータを焼きなましで求める
N と A の値からサンプリング回数を求める
サンプルの個数から大体これぐらいの mse スコアが出るよというのを事前に計算しておいて、ちょうどいい感じのサンプル個数を求める。 mse の推測値が悪かったのか N < 40 のケースだとうまくいかなかったので場合分け。もっと細かく調整できたと思うけど多分そんなスコア改善しないし面倒なのでやってない。(cover_rate は sample_count * 9 / (N * N) で計算してる)
if (N < 40) { if (cur_cost > 4000 || cover_rate > 0.13) break; } if (N >= 40) { if (g_exp_mse[N - 20][sample_count] < g_exp_mse[N - 20][sample_count + 1] + sample_cost) break; }
mse の推測値
python の curve_fit を使って自分のソルバーがサンプルを取得した数に対してどれぐらいスコアが出るのかを予測する。スコアのグラフが指数関数に似てたのでそれで近似を行う。与えるデータは自分のローカルで何個か計算しておく。
# 指数関数を定義します def exponential_function(x, a, b, c): return a * np.exp(-b * x) + c def fit_exponential_function(x_data, y_data): # パラメータの初期値を提供します initial_guess = initial_guess_from_data(x_data, y_data) popt, _ = curve_fit(exponential_function, x_data, y_data, p0=initial_guess) return popt def calculate_score(sample_count, a, b, c): return a * np.exp(-b * sample_count) + c def initial_guess_from_data(x_data, y_data): # a, b, c の初期値を直接データから求める # a の初期値は y_data の最大値、b の初期値は 0.01 (小さな正の値)、c の初期値は y_data の最小値 a = max(y_data) b = 0.01 c = min(y_data) return a, b, c
こんな感じでデータを取って
sample_count,score 5,21483.71434 7,13698.45827 10,8337.7041 15,5314.86126 20,3673.76252 25,2867.07684 40,1446.79279 60,1007.06145 80,664.26452
こんな感じの結果が得られる
sample_count,predicted_score 1,43128 2,35842 3,29836 4,24884 5,20802 6,17437 7,14663 8,12375 9,10490 10,8936 11,7654 12,6598 13,5727 14,5009 15,4417 16,3929 17,3527 18,3195 19,2922 20,2697 . . .
この結果をコードに埋め込んで利用する。N ごとにデータを取ろうとしたけど途中で面倒になったので 5個飛ばしでデータを取った。(なので N = 59 の場合は N = 60 の結果を利用してたりする)
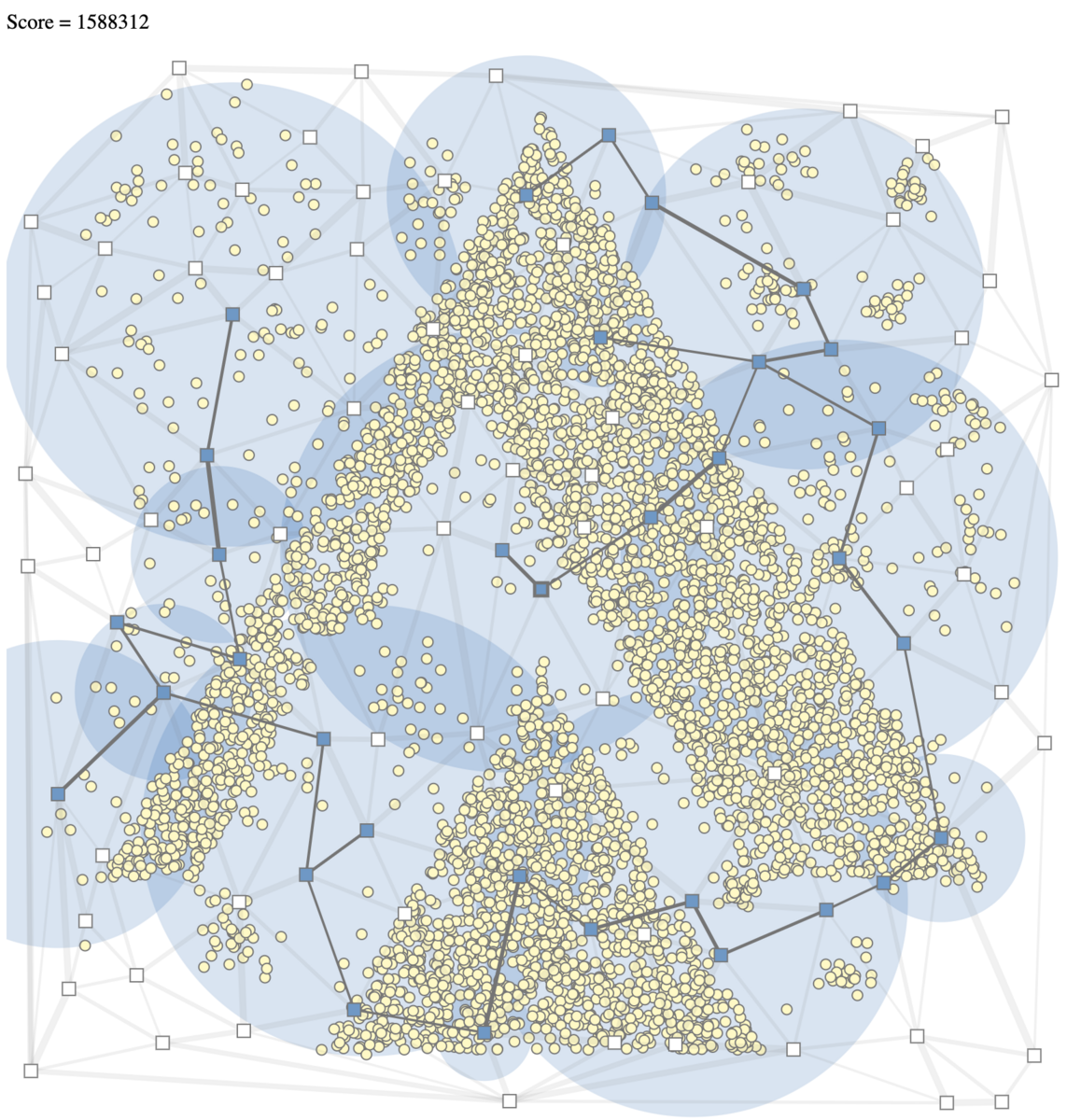
クエリーの投げる位置を焼きなましで調整
クエリーを投げる位置について焼きなましで調整した。
近傍は「ランダムにクエリの位置を変える」の 1つで、スコアは「各セルごとの一番近いクエリの箇所の距離の合計値」を計算してこれが最小になるようにした。

計算自体は BFS で行ってて最初の step は 8方向、あとは 4方向に移動
方程式のパラメータを焼きなましで求める
方程式の数は 50 で固定。遷移としては 3つ
- ランダムに方程式を生成する (どの確率で生成するかはテスターの実装と一緒)
- offx, offy を少し変更
- rx, ry を少し変更
これらの変更のあとに得られたグリッドの値をクエリーによって得られた正しい値を比較してその差分が小さくなるように調整していく。50 で固定しているせいで、E が小さいケースにめちゃめちゃ弱いけど自分では E を推定することができなかったので仕方ない。
感想
推定系は毎回苦手。 rhoo さんの解法 を見て「へぇ〜 UNet なるものがあるのか」と思った。大きな差で負けてるので何か見落としてるだろうなと思ってたけどそもそも自分の知識にないものだったので次頑張ろうという気持ちになった。あと、自分だけみたいだったけど artifacts がダウンロードできなくてサーバー側でどれぐらいの速度で動いているかが確認できなくて地味に不便だった。途中ジャッジサーバが止まってたけど停電で落ちてたっぽい。
seed 1 - 10 のスコア
Score = 23559.635786576706 Score = 1726.0470920138887 Score = 7705.3169154104025 Score = 7504.327035433278 Score = 8597.371075943804 Score = 2932.7803554454154 Score = 8497.537837936074 Score = 13487.69213050256 Score = 3508.515444010831 Score = 5008.201252074448